

Training autonomous vehicles with XR simulation
Self driving cars are a good example of what artificial intelligence can accomplish today. Such tech-centered advances are built on the back of highly trained Machine Learning (ML) algorithms.
These algorithms require exhaustive data that help the AI effectively model all possible scenarios. Accessing and pooling all that data needs complex and very expensive real-world hardware setups, aside from the extensive time it takes to gather the necessary training-data in the cloud (to train ML). Additionally during the learning process, hardware is prone to accidents, wear and tear which raises the cost and lead time in training the AI.
 Technology leaders like GE have side stepped this hurdle by simulating real world scenarios using controlled-environment setups. This controlled environment simulations coined the term ‘Digital Twins’. A digital twin can model a physical object, process, or person with abstractions that might be necessary to bring the real world behaviour in digital simulation. This is useful to data scientists who model and generate the needed data to train complex AI in a cost effective way.
Technology leaders like GE have side stepped this hurdle by simulating real world scenarios using controlled-environment setups. This controlled environment simulations coined the term ‘Digital Twins’. A digital twin can model a physical object, process, or person with abstractions that might be necessary to bring the real world behaviour in digital simulation. This is useful to data scientists who model and generate the needed data to train complex AI in a cost effective way.
An example is GE’s Asset Digital Twin – the software representation of a physical asset (like turbines). Infact, GE was able to demonstrate a savings of $1.6 billion by using digital twins for remote monitoring.
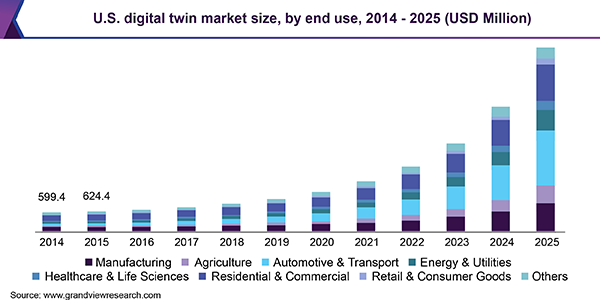
Research predicts the digital twin market will hit $26 billion by 2025, and major consumers of this technology being the automotive and manufacturing sector.
Tools at hand for digital twins
Through experimentation, Extended Reality (XR) and tools used to create XR have been found best suited to leverage digital twins with ease. Also, one of the most popular tools used to create digital twins is [Unity3D], also mentioned in ThoughtWorks Technology Radar.
Unity3D ensures an easier production of AI for prototyping in robotics, autonomous vehicles and other industrial applications.
Use case: autonomous vehicle parking
Self driving cars have a wide domain of variables to consider — lane detection, lane following, signal detection, obstacle detection etc. In our experiment at ThoughtWorks, we attempted to solve one of the problems; train a typical sedan-like-car to autonomously park itself in a parking lot through XR simulation.
The outcome of this experiment only produced signals such as the extent of throttle, brake and steering needed to successfully park the car in an empty lot. Other parameters like the clutch and gear shift were not calculated as they were not needed in the simulation. The outcome was applied in the simulation environment by a car controller script.
This simulation was made up of two parts, one was the car or the agent and the second was the environment within which we were training the car. In our project, the car was prefabricated (CAD model of car) and attached with a Rigidbody physics element (that simulates mass and gravity during execution).
The simulated car was given the following values:
A total body mass was about 1500kg
A car controller with front wheel drive
Brake on all 4 wheels
Motor Torque of 400
Brake Torque of 200
Max. steering angle of 30 degrees
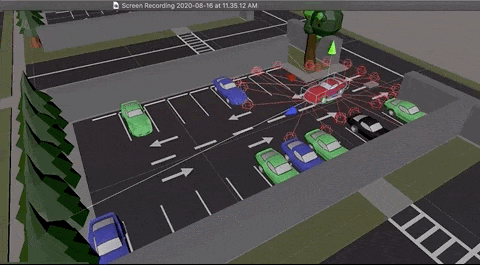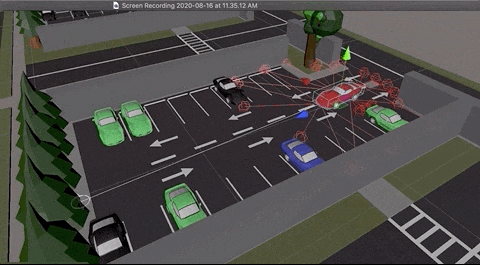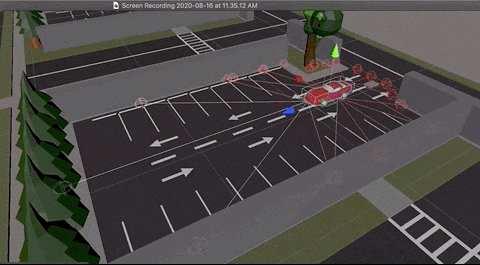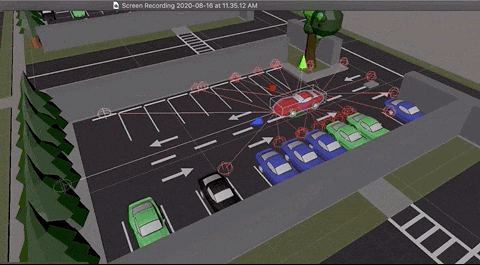
Ray cast sensors (rays projecting out from the car body for obstacle detection) in all four directions of the car. In the real world, ray cast sensors would be the LIDAR-like vision sensors.
The picture below, displays the ray cast sensors attached to the car:
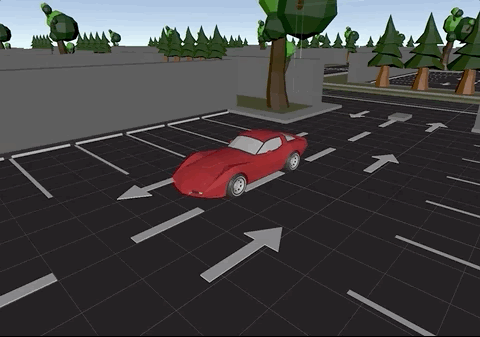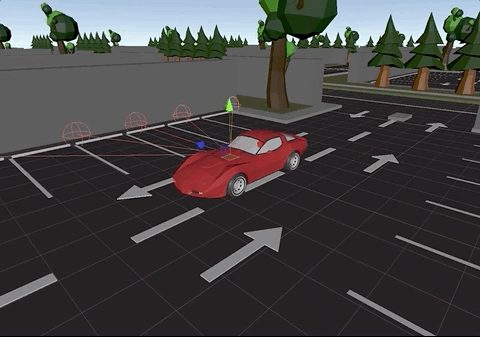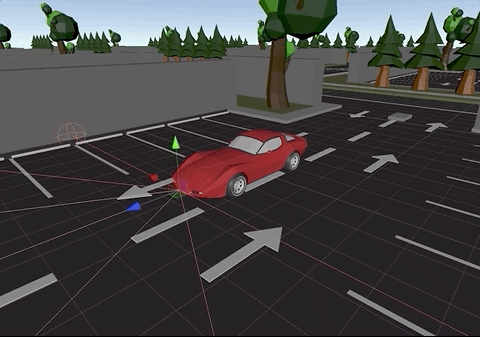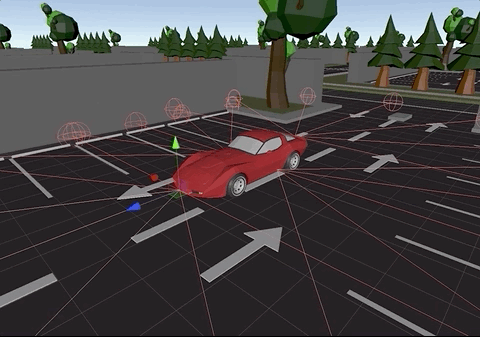
Raycast sensors in all sides of the car to detect obstacles

Ray cast sensors in action during simulation
The car’s digital twin was set up in the learning environment. A neural network configuration of four hidden layers and 512 neurons per hidden layer was configured. The reinforcement training was configured to run 10 million cycles.
The Reinforcement Learning (RL) was set up to run in episodes that would end or re-start based on the following parameters:
- The agent has successfully parked in the parking lot
- The agent has met with an accident (hitting a wall, tree or another car)
- The episode length has exceeded the given number of steps
For our use case, an episode length of 5000 was chosen.
The rewarding scheme for RL was selected as follows:
- The agent receives a penalty if it meets with any accident and the episode re-starts
- The agent receives a reward if it parks itself in an empty slot
- The ‘amount of reward’ for successful parking was based on:
- How aligned the car is to the demarcations in the parking lot
- If parked facing the wall, the agent would receive a marginal reward
- If parked facing the road (so that leaving the lot is easier), the agent would receive a large reward
A training farm was set up with 16 agents to speed up the learning process. A simulation manager randomized the training environment with parking lots having varying lot occupancy and the agent was placed at random spots in the parking area between episodes – to ensure the learning covered a wide array of scenarios.
Reinforcement learning with multiple agents parallelly
The tensor graph after 5 million cycles looked like this:
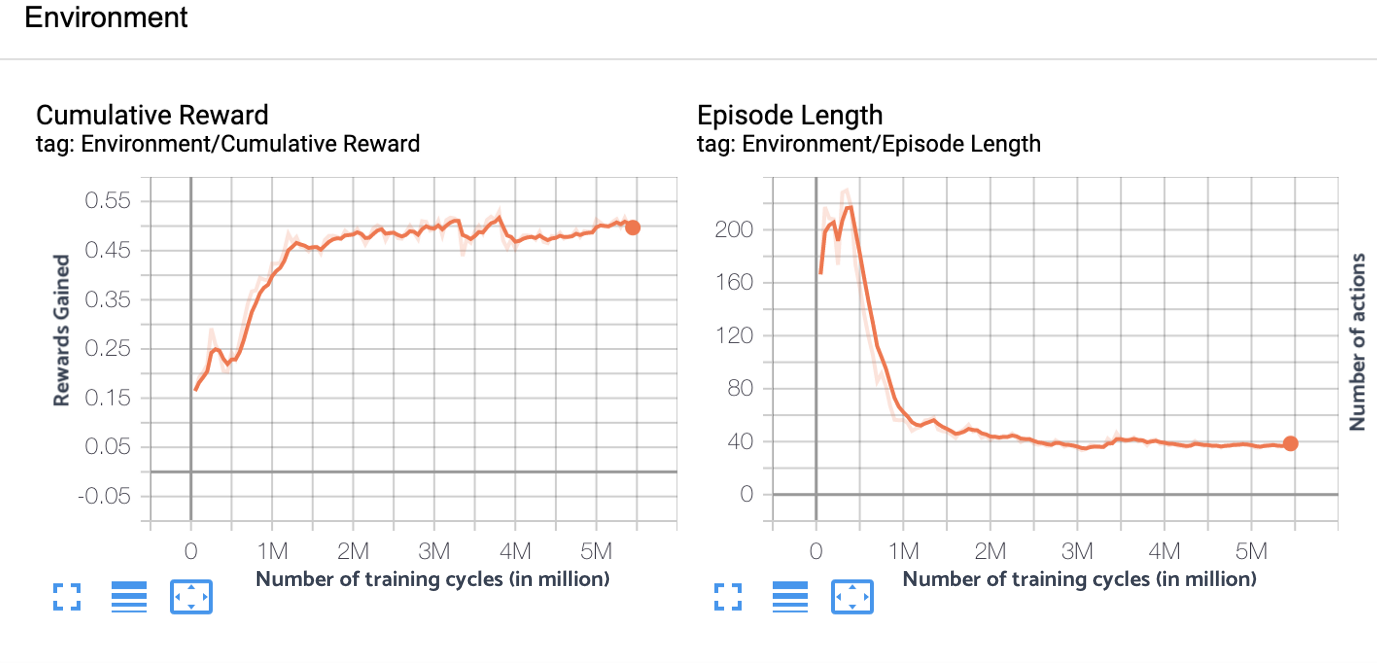
Not only had the agent increased its reward, it had also optimized the number of steps to reach the optimal solution (right hand side of graph). On an average it took 40 signals (like accelerate, steer, brake) to take the agent from the entrance to the empty parking lot.
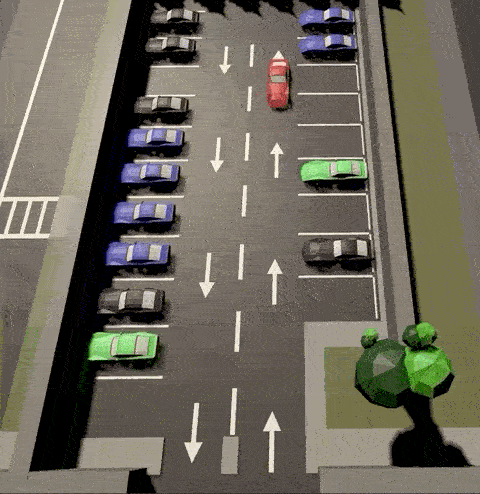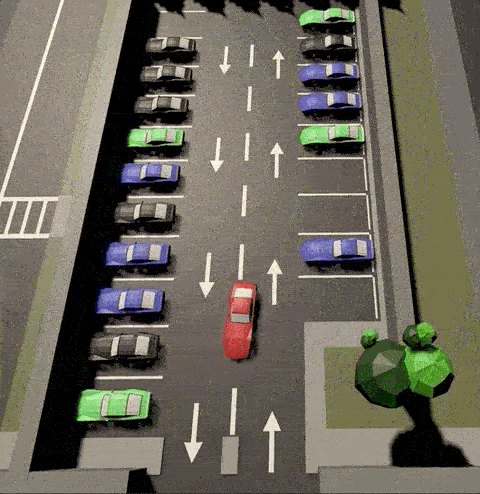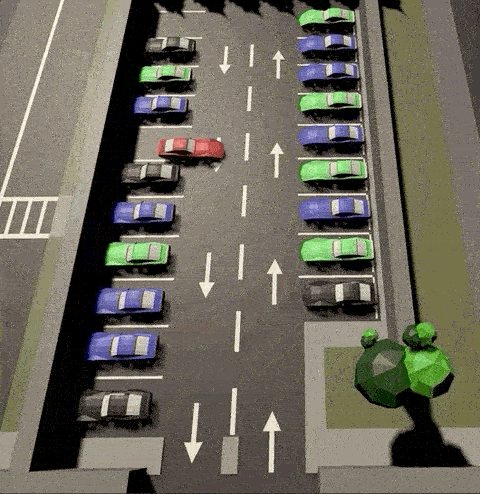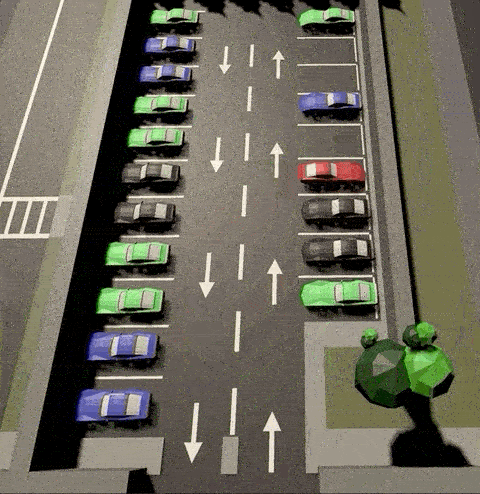
Here are some interesting captures taken during training:

Agent has learnt to park both side of the parking lot

Agent learnt to take elegant maneuvers by reversing
Agent learnt to park from random locations of the lot
Way forward
We’ve just looked at how digital twins can effectively fast track production of artificial intelligence for use in autonomous vehicles at a prototyping stage. This applies to the industrial robotics space as well.
In robotics, specifically, the digital twins approach can help train better path-planning and optimization for moving robots. If we model the rewarding points around the Markov decision process, we can save energy, reduce load and improve cycle time for repetitive jobs – because the deep learning mechanisms maximize rewards in a lesser number of steps where possible.
In conclusion, XR simulation using digital twins to train ML models can be used to fast track prototyping AI for industrial applications.
About the Author :

Mr. Kuldeep Singh
Head of XR Practice
ThoughtWorks
![]()
Kuldeep has built his career empowering businesses with the Tech@Core approach. He has incubated IoT and AR/VR Centres of Excellence with a strong focus on building development practices such as CICD, TDD, automation testing and XP around new technologies.
Kuldeep has developed innovative solutions that impact effectiveness and efficiency across domains, right from manufacturing to aviation, commodity trading and more. Kuldeep also invests time into evangelizing concepts like connected worker, installation assistant, remote expert, indoor positioning and digital twin, using smart glasses, IoT, blockchain and ARVR technologies within the CXO circles.
He has led several complex data projects in estimations, forecasting and optimization and has also designed highly scalable, cloud-native and microservices based architectures.
He is currently associated with ThoughtWorks, as a Principal Consultant, Engineering and Head of XR Practice, India. He has worked with Nagarro as a Director of Technology.
Kuldeep holds a B.Tech (Hons) in Computer Science and Engineering from National Institute of Technology, Kurukshetra. He also spends his time as a speaker, mentor, juror and guest lecturer at various technology events, and x-member of The VRAR Association. He is also mentor at social communities such as Dream Mentor, tealfeed.com and PeriFerry
Mr. Kuldeep is Accorded with the following Honors & Awards :
https://www.linkedin.com/in/ku
Mr. Kuldeep is Bestowed with the following Licences & Certifications :
https://www.linkedin.com/in/ku
Mr. Kuldeep is Volunteering in the following International Industry Associations & Institutions :
https://www.linkedin.com/in/ku
He can be Contacted at:
E-Mail : [email protected] / [email protected]
Linkedin : https://www.linkedin.com/in/ku
Twitter : https://twitter.com/thinkuldee
Facebook : https://www.facebook.com/kulde
Instagram : https://www.instagram.com/acco
Blog : https://medium.com/xrpractices
Personal Website : https://thinkuldeep.com/
Company Website : https://www.thoughtworks.com/p
About the Author:

![]()
Raju is an innovator and tech enthusiast. His passion lies in disrupting the XR (AR/VR/MR) and industrial robotics arena. He has designed real-time high-transaction rate enterprise systems and telemetry solutions.
Raju has also built a cutting edge tech start-up from the ground up. He has helped CAD and geospatial businesses realize their production and quality goals through a combination of high quality design and development of automation tools and applications.
He holds an MS in Software Systems from the Birla Institute of Technology and Science, Pilani.
Raju also spends his time as a mentor, speaker and jury at various technology events.
Mr. Raju is also Associated with the following Projects :
https://www.linkedin.com/in/ra
He can be contacted at :
Email : [email protected] / [email protected]
LinkedIn : rajukandasamy
Twitter : rajukandasamy
Blog : https://medium.com/@raju.kandasamy
Company Website : https://www.thoughtworks.com/profiles/raju-kandaswamy
Also read their earlier articles :












{kind=link}