

MQTT Sparkplug and Apache Kafka Streamline Data Flow from the Plant to
Decision-Making
With the exponential growth of data being generated at the edge of the network, the challenge of finding efficient solutions to manage this data becomes more pressing. MQTT Sparkplug and Apache Kafka, with their complementary strengths, present an ideal combination to address this challenge. These technologies allow industrial data to be integrated with any application or system, delivering the information in the required format. But how do they work together to improve the efficiency of data transfer and processing in industrial environments? And how do they enable scalable, flexible, and efficient solutions for the real-time collection and analysis of large volumes of data? This article answers these questions.
After introducing IIoT’s main data and connectivity challenges, we cover the key characteristics of Sparkplug and Kafka. Then, we show how they complement each other to seamlessly integrate operational technology (OT) and information technology (IT) data. Finally, we cite real-world IIoT use cases where combining these technologies significantly improved operational efficiency and data analysis.
The IIoT Challenge: Bridging the OT-IT Divide
The Industrial IoT represents a paradigm shift in how industries collect, process, and analyze data from their operational environments. In factories, power plants, and other industrial assets, connectivity can be limited and data volumes are extremely high. Such environments require technologies that can handle large volumes of real-time data and bridge the gap between data processing in the edge and the cloud.
From sprawling manufacturing facilities to distributed renewable energy plants, the sheer volume and velocity of data generated by industrial processes present unique challenges:
1. Real-time data collection: Industrial processes often require split-second decision- making based on current conditions.
2. Limited connectivity: Many industrial environments suffer from unstable or low-bandwidth network connections.
3. Device heterogeneity: IIoT networks often comprise a diverse array of sensors, actuators, and legacy equipment.
4. Scalability: As operations grow, IIoT solutions must seamlessly scale to handle millions of data points.
5. Data contextualization: Raw sensor data must be enriched with metadata to be truly actionable.
6. Long-term storage and analysis: Historical data is crucial for trend analysis, predictive maintenance, and other ML and AI applications.
MQTT Sparkplug: Efficiency and Contextualization in Data Transfer
The Sparkplug specification addresses many of the challenges faced at the OT level of IIoT deployments. Because it makes MQTT-based infrastructure interoperable, Sparkplug is increasingly adopted by the energy, oil and gas, manufacturing, automotive, and supply chain & logistics industries.

By leveraging MQTT Sparkplug at the edge, and through Sparkplug’s plug-and-play functionality, industrial organizations can speed up deployment and onboarding of new sites. This facilitates scalable IIoT architecture design that bridges the gap between operational technology (OT) and information technology (IT) systems.
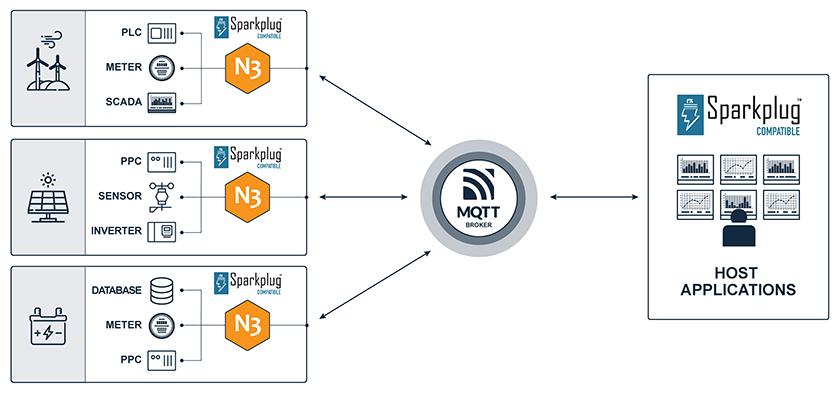
Key Strengths of Sparkplug
MQTT Sparkplug is commonly used in IIoT applications for several key reasons:
1. Efficient data transmission: Sparkplug optimizes MQTT for industrial use cases by defining a standard payload format and topic structure. This allows for more efficient transmission of data from edge devices, reducing bandwidth usage.
2. Auto-discovery: Sparkplug provides built-in mechanisms for node, device, and data model auto-discovery, making it easier to integrate new devices and sensors into an existing IIoT system.
3. Interoperability: By standardizing the data format and communication protocol, Sparkplug enhances interoperability between different industrial IoT devices, systems, and applications.
4. State awareness: Sparkplug implements state management features, allowing the system to track the status of edge devices and maintain data integrity even during network disruptions.
5. Legacy system integration: Edge nodes using Sparkplug can act as gateways, converting data from industrial protocols (e.g., Modbus, OPC UA, DNP) into the Sparkplug format, enabling seamless integration of older equipment into modern IIoT architectures.
6. Scalability: The lightweight nature of MQTT combined with Sparkplug‘s efficient data handling makes it well-suited for large-scale deployments with numerous edge devices.
7. Real-time communication: MQTT’s publish-subscribe model facilitates real-time data exchange between edge devices and central systems, which is crucial for many industrial applications.
8. Security: Sparkplug leverages MQTT’s security features, including authentication, authorization, and encryption via SSL/TLS. It ensures secure connections, data integrity, and access control. The specification also benefits from MQTT’s session management and TCP/IP’s inherent security measures.
9. Data loss avoidance: Sparkplug’s Store & Forward mechanism prevents data loss by storing data during communication disruptions.
Limitations of Sparkplug
While MQTT Sparkplug offers many advantages for industrial IoT applications, it also has some potential drawbacks to consider:
1. Limited flexibility: The standardized payload format, while beneficial for interoperability, may be restrictive for some specialized applications that require custom data structures.
2. Protobuf Usage: While Protobuf improves performance and data compactness, it can complicate integration with systems that use different serialization formats, requiring additional conversion layers.
3. Single Primary Application: Designed primarily for SCADA applications, Sparkplug 3.0 allows only a single Host Application (SCADA/IIoT Host) to be configured as the Primary Application. Selecting the Primary Application can be challenging in complex or distributed systems with multiple host applications, as a failure of the Primary Application might impact the entire system.
Apache Kafka: Scalable Real-Time Data Streaming for the IIoT
Apache Kafka can handle millions of messages per second with minimal delay, which is vital for real-time industrial applications. It has features that make it resilient to failures and capable of maintaining data integrity even in challenging conditions.
For industrial organizations, Kafka’s distributed streaming platform can serve as the backbone for handling massive volumes of real-time IIoT data.
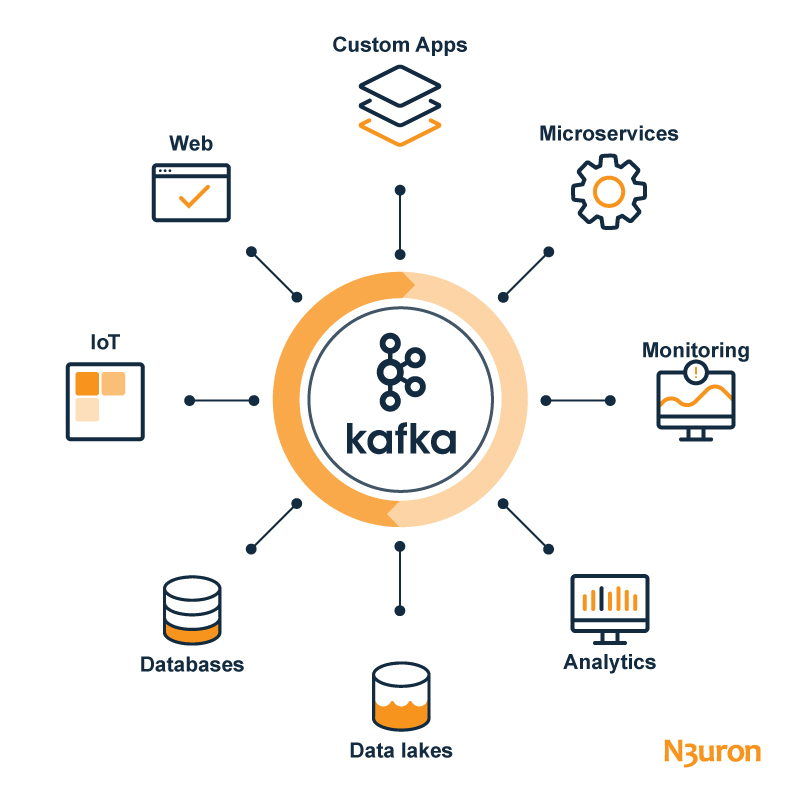
Key Strengths of Kafka
Here’s why Kafka creates a flexible and extensible IIoT data pipeline that can evolve with changing needs:
1. High throughput and low latency: Kafka is ideal for managing large volumes of data with high efficiency and in near real-time, making it perfect for industrial processes that require near real-time responses.
2. Scalability: Kafka’s distributed architecture allows it to scale horizontally, accommodating growing data volumes as IIoT deployments expand.
3. Data persistence: Kafka’s data persistence and event storage capabilities allow businesses to perform advanced analytics and store large amounts of data for future use.
4. Fault tolerance: With built-in replication and partition leadership, Kafka ensures high availability and data durability.
5. Ecosystem integration: Kafka’s rich ecosystem of connectors enables advanced integration with other enterprise platforms such as Apache Flink and Spark, facilitating the extraction of key insights for analysis and visualization.
6. Decoupling data producers and consumers: Data producers can push data to Kafka without worrying about the specific consumers and their requirements. Similarly, consumers can subscribe to relevant topics in Kafka and consume the data at their own pace, independent of when it was produced.

Limitations of Kafka
While Kafka delivers many benefits for IIoT applications, it does have some limitations:
1. Complex for edge deployments: Kafka’s distributed nature and resource requirements make it less suitable for direct deployment on resource-constrained edge devices. It is not optimized for millions of simultaneous connections from low-power devices or unstable networks, as is common in many IIoT environments.
2. Requires stable networks: Kafka performs best in environments with reliable, low-latency, and high-bandwidth network connections. This limits its application in scenarios where connectivity may be inconsistent or intermittent.
3. Complex to manage and operate reliably: In IIoT scenarios, which typically comprise edge devices and multiple data centers, setting up, configuring, and maintaining Kafka can be complex. Its computational requirements can be challenging in IIoT environments where edge devices may have limited resources, and operating Kafka reliably requires specialized knowledge and skills.
The Perfect Bundle for IIoT Performance and Scalability
Sparkplug and Kafka can be combined to deploy a robust, future-proof, efficient architecture end-to-end, for IIoT data management. The bundle solution is perfect for consistent data streaming between the plant floor and enterprise applications and services. The two technologies have complementary strengths. Where one falls short, the other excels:
- Sparkplug: Excellent for real-time device connectivity and efficient data management in limited networks, but with limitations in advanced data integration and persistent storage
- Kafka: Kafka excels at high-throughput, distributed event streaming and message processing. Though it supports an infinite retention period, it does not replace a database or data lake but rather acts as a buffered message queue.
Here’s how Sparkplug and Kafka complement each other in IIoT architectures:
- Sparkplug efficiently collects real-time data from devices and sends only relevant data to Kafka.
- Kafka’s robust integration capabilities allow it to seamlessly connect with various corporate applications and services, acting as a central hub for data flow.
What would a hybrid Sparkplug-Kafka architecture look like? Here is an example. In the middle is N3uron SparkPipe, a plug-and-play, no-code, zero-ETL solution that enables seamless integration between Sparkplug (OT) data and cloud services to accelerate digital transformation.
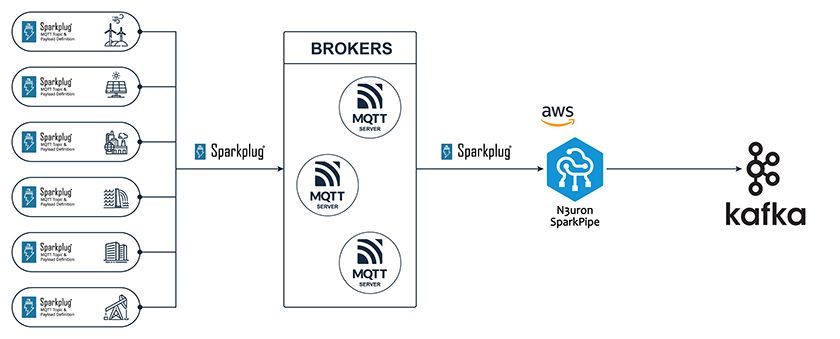
While Sparkplug handles the complexities of device communication and data transmission at the OT level, Kafka provides a scalable, IT-friendly interface for accessing and processing this data. For remote or bandwidth-constrained sites, local Sparkplug gateways can aggregate data before forwarding to centralized Kafka clusters.
Real-World Use Cases: Successful Implementations
Now let’s cover some use cases where industrial organizations are bundling Sparkplug and Kafka to enhance their IIoT operations.
Power plants: Solar energy companies are improving efficiency and responsiveness by integrating Sparkplug for real-time data capture and Kafka for mass data management. Their systems are often inefficient for the large amounts of data they need to consume — bandwidth usage is often extremely high, and the data can’t be retrieved fast enough to meet their requirements. Leveraging Sparkplug enables them to move data securely and efficiently from the OT layer upstream to Kafka.
Automotive Factories: Automotive manufacturers are bundling Sparkplug and Kafka to achieve reliable message delivery from the factory to the cloud. They are using Sparkplug to integrate diagnostic devices in order to obtain real-time data and deep analysis via Kafka. Such manufacturers often have a diagnostic system that needs to remain running at all times to coordinate production for commissioning and testing car control units. A Sparkplug–Kafka solution can ensure correct test device behavior when a network connection is dropped and reconnected.
Smart grid management: Energy companies who have smart meters and a device gateway can consume the data with Kafka and pre-filter it there before sending the aggregated data of interest to an asset monitoring tool. Smart meters connected to a Sparkplug-enabled gateway provide granular, real-time data on power consumption and distribution network status. Kafka streams can process this data to support dynamic load balancing and demand response; fault detection and predictive maintenance; and integration with renewable energy sources.
Predictive Maintenance: Manufacturers are deploying Sparkplug–Kafka solutions to support predictive maintenance. Predictive maintenance—which delivers cost savings over routine or preventive maintenance—requires reliable, scalable, and real-time infrastructure and software. The integration of Sparkplug and Kafka creates a foundation for sophisticated predictive maintenance models. It not only improves the accuracy and timeliness of maintenance predictions but also enables adaptive maintenance scheduling based on actual equipment conditions rather than fixed intervals.
Operational Data Integration for Better Trading Decisions: Integrating operational data can significantly enhance energy trading strategies. Real-time data from devices like smart meters and sensors, processed with Kafka, helps in demand forecasting, proactive maintenance, and optimized energy distribution. Adding Sparkplug to this architecture results in an accurate, real-time view of energy production and consumption patterns, enabling traders to make informed decisions in volatile energy markets.
Quality Assurance and Yield Management in Manufacturing: Sparkplug-enabled edge devices (e.g., quality sensors, and machine vision systems) can be deployed throughout the production line. They can be configured to process and analyze quality data locally, sending only significant events or aggregated data to Kafka. To improve Overall Equipment Effectiveness (OEE), Kafka is used to monitor quality metrics in real time, enabling proactive measures to maintain quality standards, minimize defects, and optimize production yield.
The Future of IIoT with Sparkplug and Kafka
Industrial and energy companies have an increasing business-critical need for operational efficiency, predictive maintenance, and real-time decision-making. As they strive to modernize their operations, the integration of smart sensors, real-time analytics at scale, and robust communication protocols will become paramount.
At the heart of this shift towards a more connected and data-driven industrial landscape, Sparkplug and Apache Kafka are set to play fundamental roles in facilitating seamless data flow and processing.
Sparkplug will standardize how industrial devices and applications communicate, ensuring interoperability and efficient data exchange across diverse systems.
Apache Kafka’s distributed streaming platform will serve as the backbone for handling massive volumes of real-time data generated by IIoT devices and systems.
Together, these technologies will enable industrial companies to create scalable, reliable, and flexible data pipelines that can rapidly ingest, process, and analyze information from countless sensors and devices, paving the way for more intelligent and responsive industrial operations.
By leveraging Sparkplug’s strengths in edge connectivity and data contextualization with Kafka’s prowess in high-throughput data streaming and processing, organizations can create robust solutions that bridge the OT-IT divide.
Try N3uron Sparkpipe: A No-Code, Zero-ETL Sparkplug-Kafka IIoT Solution
Looking to implement a solution that combines the best of Sparkplug and Kafka to optimize the performance and scalability of your IIoT systems? Explore SparkPipe on AWS Marketplace, a solution designed to enhance the integration of these technologies into your infrastructure.
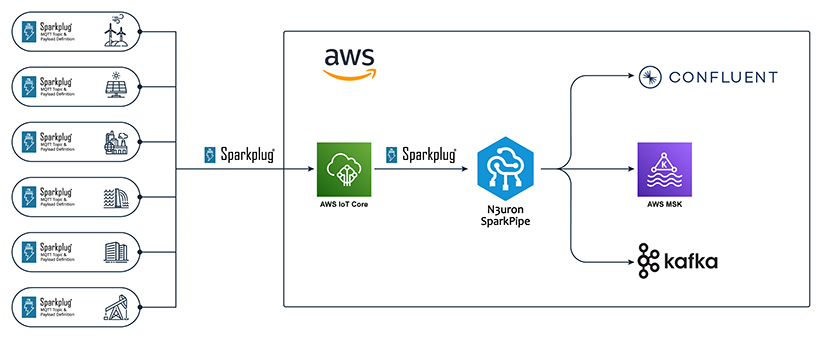
Using the SparkPipe connector for Apache Kafka, you can publish all the real-time IIoT data in your existing infrastructure to a Kafka broker using an easy-to-parse JSON payload ready to be consumed.
SparkPipe is a cutting-edge connectivity solution for Industrial IoT to bring OT data, using Sparkplug, into cloud services. It seamlessly bridges operational data at the edge with advanced data processing in the cloud to enable data-driven applications, stream processing, advanced analytics, machine learning, and more.
Sparkpipe was created by N3uron, a software development company that provides industrial software solutions that enable organizations to manage their data effectively and efficiently while reducing technological and financial constraints.
SparkPipe is compatible with any Sparkplug-enabled client. With SparkPipe, you can accelerate your IIoT deployment and unlock the full potential of your industrial data. .

About the Author

Business Strategist | IIoT & Emerging Technology Advocate | Industry 4.0 & Digital Transformation Enthusiast | SCADA & Asset Management Expert | Edge Computing | IIoT Cybersecurity | Ignition Firebrand Award Winner
![]()
With over 20 years of experience in industrial automation and system integration, Mr. Jose Granero has performed diverse technical and strategic roles throughout his career, mainly in multinational companies.
Mr. Jose Granero is passionate about using technology to drive innovation and bridge the gap between data and operations.
Mr. Jose Granero is the Head of Business Strategy and Customer Experience at N3uron Connectivity Systems. In his current position, he is focused on company strategy, customer and partner success and product management.
Mr. Jose Granero holds a Master of Science degree in Industrial Engineering from the Polytechnic University of Madrid and a Master in Project Management from the School of Industrial Engineers of Madrid.
Mr. Jose Granero can be contacted at:
Also read Mr. Jose Granero’s earlier article:








{kind=link}