
Implementing MCP for Enhanced Prompting and RAG-Based Applications
Imagine having a conversation with someone who forgets everything you said just seconds ago. Frustrating, right? This is how traditional AI models often behave—they generate responses based only on the immediate input, without remembering previous interactions.
The Model Context Protocol (MCP) is designed to solve this problem. It acts like a memory layer for AI models, ensuring they can retain context, track conversations, and make more relevant and consistent responses.

At its core, MCP helps AI systems understand and remember past interactions, making them smarter, more reliable, and context-aware. Instead of treating every question as a standalone request, MCP allows AI to connect the dots—just like how humans recall past discussions to give better answers.
Why is Context Preservation Important in AI Applications?
Context is what makes human conversations flow naturally. Imagine asking a customer support chatbot:
User : “What’s the status of my order?”
Bot : “Could you provide your order ID?”
User : “Yes, it’s 12345.”
Bot : “Which order are you referring to?”
Without context, the chatbot doesn’t remember that you just provided an order ID! This makes interactions frustrating and inefficient.
With MCP, AI models can maintain context across multiple exchanges. This means:
Smoother conversations – AI remembers what was said before
Better accuracy – AI provides relevant responses based on past inputs
Personalization – AI tailors responses based on prior interactions
For applications like chatbots, virtual assistants, and customer support AI, context preservation is critical. It ensures that users don’t have to repeat themselves and that the AI can engage in more natural, intelligent conversations.
How MCP Enhances Prompt Engineering & RAG (Retrieval-Augmented Generation) Models
Improving Prompt Engineering with MCP
Prompt engineering is the technique of crafting effective instructions (or “prompts”) to guide AI in generating accurate responses. However, without MCP, each prompt is like a fresh start—AI lacks memory of previous interactions.
With MCP, prompts become dynamic and context-aware, allowing AI to remember past interactions and generate better responses.
For example, a basic LLM prompt without MCP might look like this:
“Summarize the latest news about electric vehicles.”
But with MCP, the AI can consider previous requests and refine its responses:
“Based on our previous discussion on Tesla’s new battery technology, summarize the latest news about electric vehicles.”
This leads to better relevance, more continuity, and less repetitive answers.
 Enhancing Retrieval-Augmented Generation (RAG) with MCP
Enhancing Retrieval-Augmented Generation (RAG) with MCP
Retrieval-Augmented Generation (RAG) improves AI responses by pulling in external data from knowledge bases or documents before generating an answer. However, RAG alone doesn’t remember user preferences or prior searches.
MCP enhances RAG by keeping track of user interactions, making retrieval more relevant and personalized.
Example:
Without MCP:
User: “Tell me about climate change.”
Bot: Retrieves general climate change data from Wikipedia.
With MCP:
User: “Tell me about climate change.”
Bot: Retrieves climate data from scientific journals, since the user previously asked about research-based information.
This means AI can fine-tune its knowledge retrieval based on user behaviour, making responses smarter and more contextually aware.
How MCP integrates with Prompts and RAG apps
Basic Integration
MCP can be integrated with prompts by adding specific instructions that ask the model to assess its confidence. Here’s a simple example:
![]()
Advanced Integration
For more sophisticated applications, you can structure prompts to:
1. Request multi-stage reasoning
2. Ask for confidence assessment at each step
3. Provide specific formats for confidence reporting
Example:

MCP with RAG Applications
RAG applications combine retrieval systems with generative models. Here’s how MCP enhances RAG:
1. Source Confidence: MCP helps assess the reliability of retrieved information
2. Integration Confidence: Measures how well the retrieved information applies to the query
3. Response Confidence: Overall confidence in the final generated response
Simple RAG+MCP Example
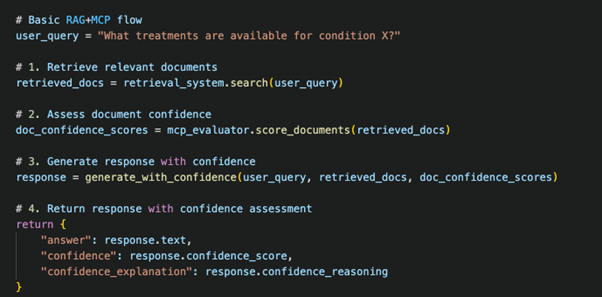
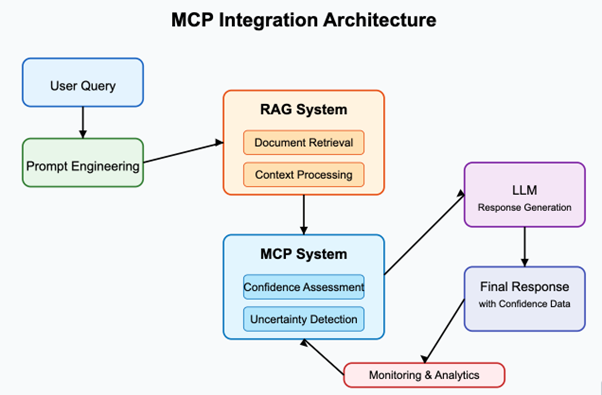
End-to-End Solution Architecture
The architecture below shows how MCP integrates into a prompt-based RAG system:
1. User Query: The starting point of the interaction
2. Prompt Engineering: Structures the query with confidence assessment instructions
3. RAG System: Retrieves and processes relevant documents
4. MCP System: Assesses confidence and detects uncertainty
5. LLM: Generates the response with confidence data
6. Final Response: Includes the answer and confidence information
7. Monitoring & Analytics: Tracks performance and provides feedback
Model Comparison Platform (MCP) is a system that helps you compare and evaluate different AI models. It lets you test models side-by-side to see which one performs best for your specific needs.
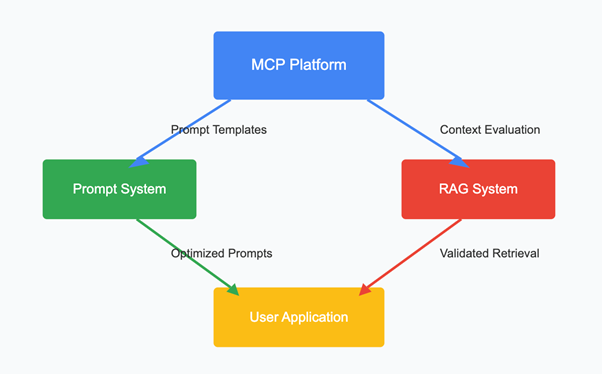
Key Integration Points
1. Prompt Optimization: MCP tests different prompt templates to find which ones get the best responses from your AI models.
2. RAG Enhancement: MCP evaluates how well your retrieval system finds relevant information and how effectively your AI model uses this information.
3. A/B Testing: Compare different versions of prompts and RAG setups to see which performs best.
4. Feedback Loop: Continuously improve your system based on real user interactions and performance metrics.
Example: Customer Support AI
Let’s say you’re building a customer support AI that answers product questions.
Without MCP:
- You write prompts based on your best guess
- You set up RAG with your product documentation
- You hope it works well for customers
With MCP:
- You create 5 different prompt templates
- You test each template with different RAG configurations
- MCP shows you which combination gives the most accurate answers
- You implement the winning combination in your application
End-to-End Solution Architecture
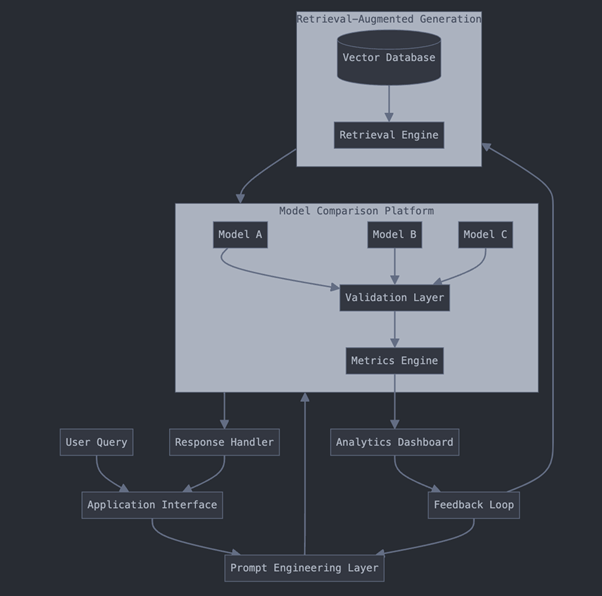
Components Explained
1. Application Interface: Where users interact with your AI system.
2. Prompt Engineering Layer: Creates and manages different prompts.
3. RAG System:
-
- Vector Database: Stores your document embeddings
- Retrieval Engine: Finds relevant information for user queries
4. MCP Platform:
-
- Multiple AI Models: Compare different models (e.g., Claude, GPT-4)
- Validation Layer: Checks responses for accuracy, relevance, etc.
- Metrics Engine: Collects performance data
5. Analytics Dashboard: Shows you how your system is performing.
6. Feedback Loop: Routes performance data back to improve prompts and RAG.

Monitoring and Analytics Tools
AI models can sometimes give inaccurate, slow, or irrelevant responses. To improve their performance, we need tools that track, analyze, and optimize AI behavior. MCP provides several monitoring and analytics tools to help developers and AI teams understand how well their system is working.
MCP provides several tools to monitor your AI system:
1. Performance Dashboard
The Performance Dashboard acts like a control panel for AI models, showing real-time statistics on how well they are performing.
Response Accuracy – How often the AI provides correct or helpful answers
Response Time – How quickly the AI replies to a user query
User Satisfaction Scores – Feedback from users about the AI’s responses
Failure Rates – How often the AI fails to generate a response or gives a bad answer
For eg.
Imagine an AI chatbot that answers customer support questions. The Performance Dashboard helps the team track:
- If users are happy with the answers (User Satisfaction Score)
- If the bot is responding fast enough (Response Time)
- If the bot is failing too often (Failure Rate)
This helps AI teams adjust and improve their models over time.
2. Prompt Effectiveness Analysis
AI models generate responses based on prompts, which are the instructions given to them. The Prompt Effectiveness Analysis tool helps identify the most effective prompts. See which prompts work best for different types of questions:
- Which prompt template gets the highest accuracy?
- Which prompt results in the fewest hallucinations?
- How do prompts perform across different user segments?
Example:
A company tests two different prompts for a chatbot:
- Prompt A: “Summarize this document in simple words.”
- Prompt B: “Give a short, clear summary of this document for a general audience.”
After analyzing responses, the team finds that Prompt B produces clearer, more accurate summaries. They decide to use it across all their AI interactions.
3. RAG Quality Metrics
Retrieval-Augmented Generation (RAG) is when AI models fetch relevant documents to improve response quality. The RAG Quality Metrics tool ensures this process works correctly. Measure how well your retrieval system works:
- Relevance of retrieved documents – Are the documents truly related to the query?
- Coverage of necessary information – Does the AI fetch enough data to answer correctly?
- Impact on final response quality – Does using retrieval improve AI responses?
Example:
A legal AI assistant uses RAG to fetch case laws before answering a legal question. If the retrieved cases are outdated or irrelevant, the assistant may give a bad answer. The RAG Quality Metrics tool flags these issues, allowing AI engineers to fine-tune retrieval settings.
4. A/B Test Results
A/B testing allows teams to compare different AI setups and see which one works better. Compare different configurations:
• Prompt A vs. Prompt B – Which generates better responses?
• RAG with 3 documents vs. RAG with 5 documents – Does fetching more data help?
• Different models using the same prompts and retrieval – Which model works best?
Example:
A company tests two AI models for customer support:
• Model A (GPT-4) with RAG fetching 3 documents
• Model B (Claude) with RAG fetching 5 documents
After running the test, they find that Model B provides better responses because fetching more documents improves accuracy. Based on this, they switch to Model B for production.
Implementing Monitoring
AI models don’t always give perfect responses—sometimes they lack confidence, make mistakes, or even “hallucinate” (generate false information). To improve AI accuracy, MCP (Model Context Protocol) provides monitoring and analytics tools that help track and refine AI performance.
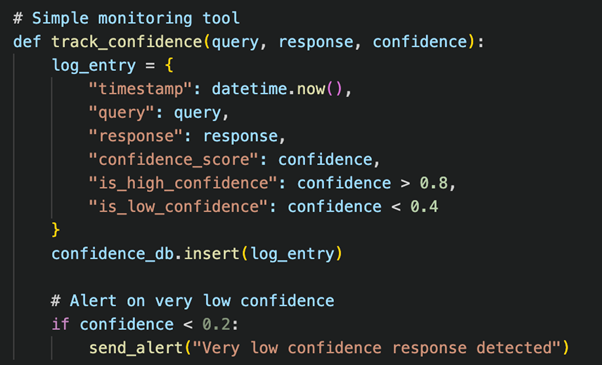
Monitoring Dashboard
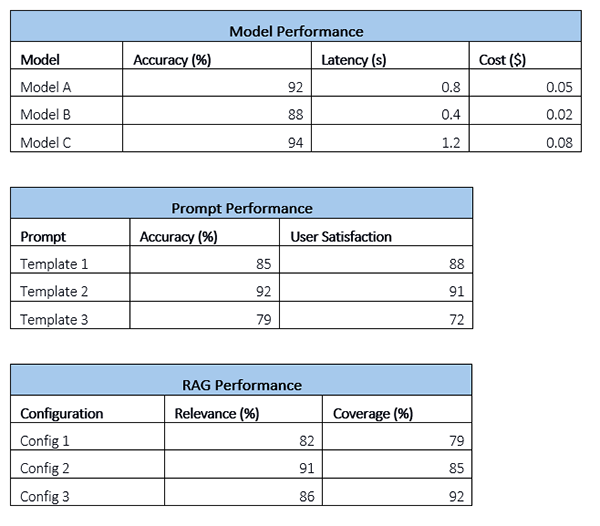
Key Insights
• Model C has highest accuracy but costs 60% more than Model A
• Template 2 shows best balance of accuracy and user satisfaction
• RAG Config 2 provides best overall performance
• Template 3 needs improvement – low user satisfaction
Comparison with Traditional AI Validation Tools
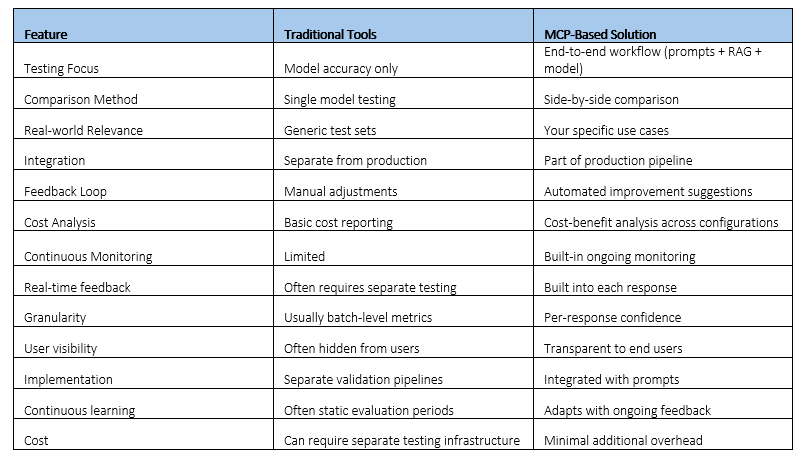
Step-by-Step Implementation with Examples
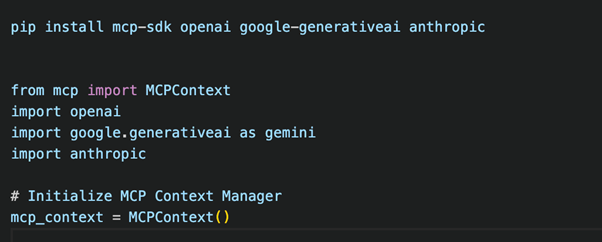
Step 1: Install MCP SDK and Set Up the MCP Context Manager
First, install the MCP SDK and initialize the MCP context manager:
Step 2: Retrieve Context and Attach it to AI Requests
Whenever a user sends a query, retrieve previous conversation history from MCP and enrich the query before sending it to the LLM.
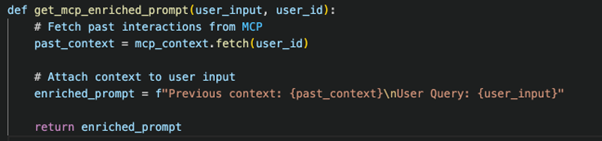
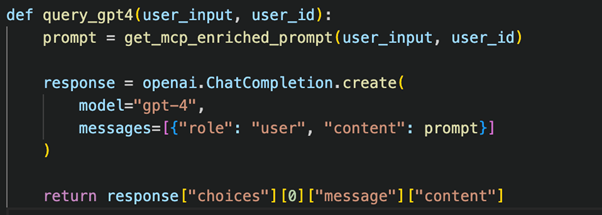
Step 3: Send Enriched Prompt to LLMs (GPT-4, Claude, Gemini)
You can send the enriched query to any LLM (GPT-4, Claude, Gemini) by modifying the API request accordingly.
Using GPT-4 (OpenAI API)
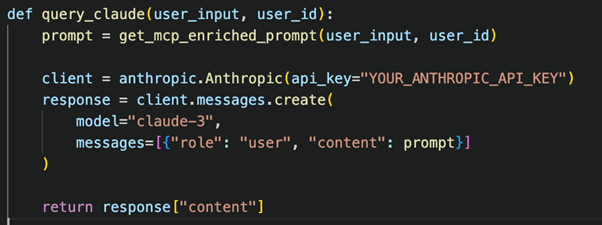
Using Claude (Anthropic API)
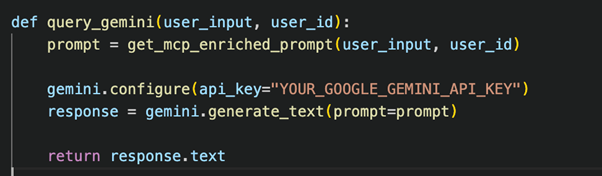
Using Gemini (Google Generative AI API)
Step 4: Store the LLM Response in MCP for Future Context
After the LLM generates a response, store it in MCP for future interactions.

Step 5: Enable Cross-Platform AI Context Sharing
If multiple AI systems need access to user history (e.g., chatbot + CRM AI), MCP allows cross-platform context retrieval.

Develop Monitoring & Analytics Tools
- Build tools to collect and analyze MCP logs. Example:
- Use Elasticsearch for log storage.
- Use Kibana for visualization.
- Monitor metrics like latency, accuracy, and confidence scores.
Step 1: Design Confidence-Aware Prompts

Step 2: Implement RAG with Confidence Assessment
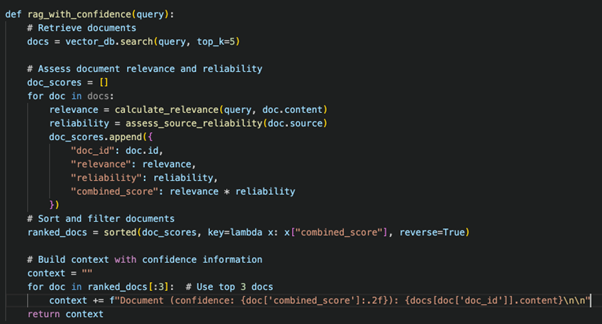
Step 3: Configure LLM for Confidence Reporting
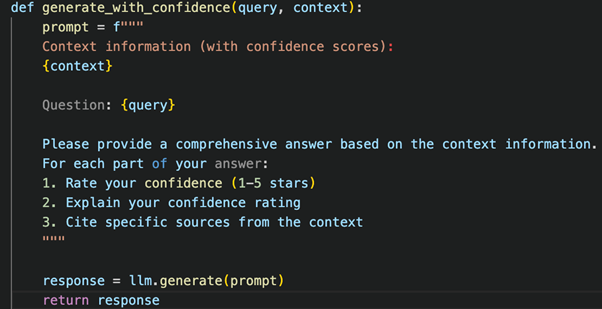
Step 4: Parse and Present Confidence Data
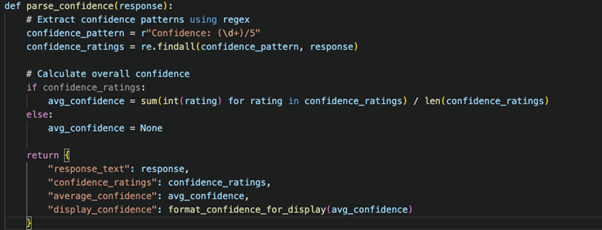
Step 5: Implement Monitoring and Feedback Loop
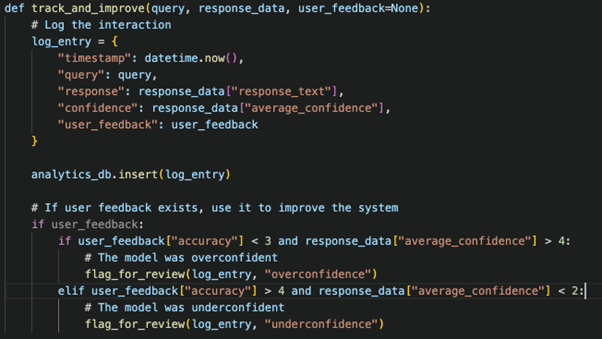
Example Use Case
Scenario: AI-Powered Customer Support
1. User Query: A customer asks, “What is your refund policy?”
2. Chatbot: The chatbot sends the query to the MCP server.
3. RAG-Based App: The MCP server queries a RAG-based app for the latest policy document.
4. External Model: The MCP server validates the response using an external validation model.
Response: The chatbot returns the validated response to the user.
The Model Context Protocol (MCP) is a game-changer for AI applications. It bridges the gap between one-time interactions and long-term memory, making AI more intelligent, human-like, and efficient.
Challenges & Best Practices in MCP Implementation
The Model Context Protocol (MCP) is a powerful way to make AI models smarter by helping them remember and understand context across interactions. However, like any technology, implementing MCP comes with challenges. In this guide, we’ll explore common hurdles and the best ways to overcome them.
1. Handling Multi-User Sessions Effectively
The Challenge:
When multiple users interact with an AI system at the same time, how does the AI keep track of who said what? If the AI mistakenly mixes up different users’ conversations, it could lead to confusing or incorrect responses.
For example, imagine a customer support chatbot where:
• User A asks about a product refund.
• User B asks about shipping updates.
If the AI confuses their conversations, User A might get shipping details, while User B gets refund instructions!
Best Practices to Solve This:
• Assign unique session IDs: Every conversation should have a user-specific session ID, so the AI knows which context belongs to whom.
• Use short-term memory per session: AI should keep context only during the session and clear it when the user leaves, preventing cross-user mix-ups.
• Implement user authentication: AI can recognize returning users by linking context to accounts, improving personalization while maintaining privacy.
2. Managing Latency with Real-Time MCP Context Retrieval
The Challenge:
MCP requires storing and retrieving a lot of contextual information to generate accurate responses. If not optimized, this extra processing time can slow down responses, leading to latency issues.
For example, if a chatbot has to pull a long conversation history before answering, users may experience a noticeable delay between asking a question and getting a response.
Best Practices to Solve This:
• Use caching: Store frequently used context in a fast-access memory cache (like Redis) instead of fetching it from a database every time.
• Limit context retrieval: Instead of pulling an entire conversation history, retrieve only the most relevant past interactions.
• Optimize database queries: Use indexed searches to retrieve stored context quickly, reducing AI response time.
• Batch processing: If multiple context updates happen simultaneously, process them in small efficient batches instead of one-by-one.
3. Security Concerns in MCP-Integrated AI Models
The Challenge:
MCP stores conversation history and contextual data. This introduces security risks, such as:
• Data leaks: Sensitive user information might get exposed if not properly protected.
• Unauthorized access: Hackers could attempt to steal stored context and use it maliciously.
• Prompt injection attacks: Malicious users might try to manipulate stored context to trick the AI into revealing private data.
Best Practices to Solve This:
• Encrypt stored context: Always use encryption (AES, TLS) when storing and retrieving context data.
• Apply access controls: Ensure only authorized users and AI systems can access stored context. Use RBAC (Role-Based Access Control).
• Monitor for anomalies: Use real-time monitoring tools to detect unusual AI responses that might indicate prompt injection attacks.
• Auto-expire sensitive data: Set expiration timers for stored context, so private information is not stored longer than necessary.
4. Best Practices for Fine-Tuning MCP with LLMs
The Challenge:
LLMs (Large Language Models) like GPT-4, Claude, and Gemini are powerful, but fine-tuning them with MCP context requires careful handling. If done incorrectly, the AI might overfit to past conversations, generate irrelevant responses, or fail to balance old and new context.
Best Practices to Solve This:
• Train on structured contextual data: Instead of raw conversation logs, fine-tune models on well-organized context-label pairs to improve learning.
• Set context prioritization rules: Teach the model to give more weight to recent context over older conversations.
• Avoid context overload: Limit how much past conversation the AI considers. Too much context can make responses slow and inaccurate.
• Test different prompt strategies: Experiment with few-shot prompting, retrieval-based prompting, and hybrid approaches to find the best way to integrate context.
Whether you’re building chatbots, AI assistants, or knowledge-based AI applications, integrating MCP with Prompt Engineering and RAG will create a more seamless, personalized, and smarter AI experience.
Implementing MCP in AI models is a game-changer, but it comes with challenges that need careful handling. By optimizing session management, improving latency, securing stored context, and fine-tuning LLMs properly, you can build AI systems that are faster, smarter, and safer.
Quick check on how MCP used
• Assign session IDs to keep user contexts separate.
• Use caching and indexing to reduce context retrieval delays.
• Encrypt stored context and apply access control to secure user data.
• Fine-tune LLMs carefully to balance relevance and performance.
About the Author:

Ms. Rajni Singh
Big Data & AI Senior Manager,
Accenture
![]()
Ms. Rajni Singh is a data and AI practitioner specializing in agentic AI systems that transform messy, multi-source data into accurate, safe decisions.
Ms. Rajni Singh expertise lies in LLMOps, RAG, LangGraph, and production-grade AI systems built with strong observability, governance, and cost/latency optimization.
Ms. Rajni Singh has led enterprise-scale GenAI programs across GCP and AWS, architecting Knowledge Layer frameworks (feature store + vector + graph) that improved accuracy by 25%, reduced cost 33%, and cut latency 23%.
Ms. Rajni Singh is the author of _Mastering Generative AI: Design Patterns, Frameworks, and Real-World Applications_ and has written over 80 technical publications on Medium, where Ms. Rajni Singh shares pragmatic insights on tracing agent reasoning, de-duplicating sources, and building guardrails that hold in production.
Ms. Rajni Singh is Accorded with the following Honors & Awards :
https://www.linkedin.com/in/si
Ms. Rajni Singh can be contacted at :
LinkedIn | Medium | Blog | E-mail | Mobile : +91 9971798831







 is designed to solve this problem. It acts like a memory layer for AI models, ensuring they can retain context, track conversations,){kind=link}